DeepSeekdeepseek-r1:8b-0528-qwen3-fp16 Ollama使用说明
简介
DeepSeek 本次更新的 R1 系列模型在数学、编程与通用逻辑等多个基准测评中取得了当前国内所有模型中首屈一指的优异成绩,并且在整体表现上已接近其他国际顶尖模型,如 o3 与 Gemini-2.5-Pro。通过思维链蒸馏技术,他们成功让一个8B参数的小模型达到了235B级别的推理性能。这不仅仅是技术上的进步,更是对整个AI模型发展方向的重新定义。 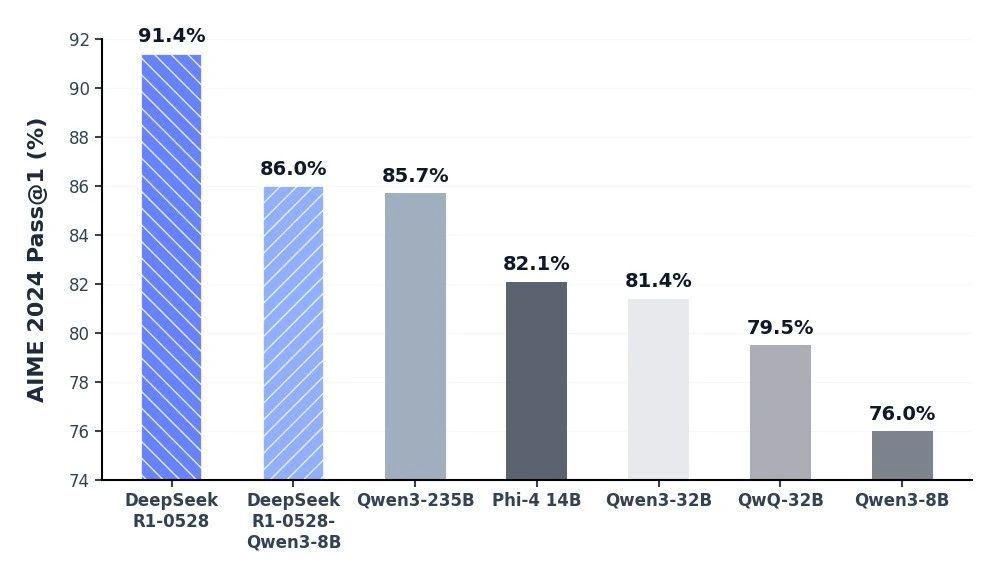
使用说明
租用4090*1,然后选择镜像deepseek-r1-0528-8b-qwen3-fp16创建实例。
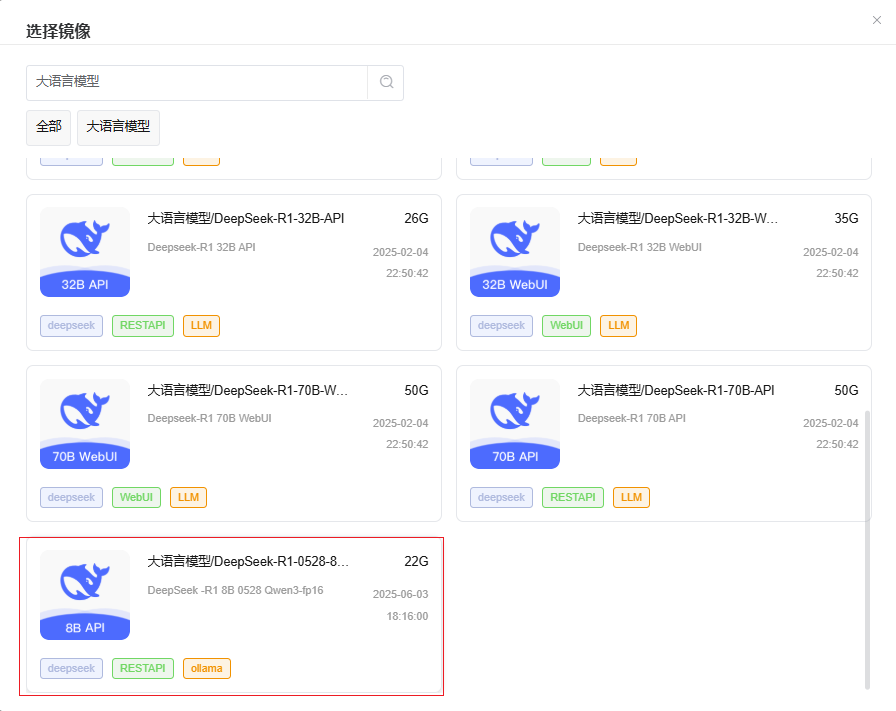
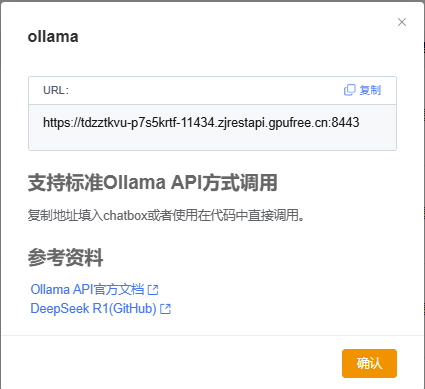
然后可以使用ollama提供的deepseek-r1-0528-8b-qwen3-fp16模型的api服务。

镜像介绍
镜像使用的ollama v0.7.0 默认开启了OLLAMA_FLASH_ATTENTION。镜像对模型名称做出了一些调整,将deepseek-r1:8b-0528-qwen3-fp16重命名为deepseek-r1-8b-0528-qwen:< tag >。
这里的tag除latest(与原模型完全相同,只是名称不同,可通过ollama cp命令进行重命名),都是指模型可支持的最大上下文长度,如126k上下文、62k上下文和30k上下文(原模型默认4k上下文),通过对原模型的Modelfile增加参数"PARAMETER num_ctx <上下文长度>"实现上下文长度的修改。
对于RAG任务或构建复杂agent一般都需要模型具有长上下文,用户可以根据实际需要选择一定上下文长度的模型,但不要盲目使用更长上下文的模型。
 关于显存 ollama使用不同的kv-cache-type可以改变显存的使用情况。
关于显存 ollama使用不同的kv-cache-type可以改变显存的使用情况。
- kv-cache-type为fp16(默认情况)时,deepseek-r1:8b-0528-qwen3-fp16模型最多支持30k上下文(对应deepseek-r1-8b-0528-qwen3:30k)
- kv-cache-type为q8_0时,模型最多支持62k上下文(对应tag为62k),kv-cache-type为q4_0时,模型最多支持126k上下文(对应tag为126k)
不同kv-cache-type代表不同的计算精度,精度要求高则使用fp16(默认值),精度要求不高可以使用q4_0,精度要求和上下文要求均衡可以使用q8_0。
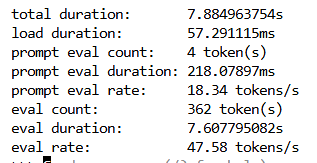
在kv-cache-type一定时,若上下文长度不超过测试出的最大值,则ollama推理模型时可以充分使用GPU推理模型,例如:

在单张4090显卡上充分使用GPU推理该模型的输出速度都在47tokens/s左右,非常流畅。