快速开始
资源需求
| 资源 | 数量 |
|---|---|
| RTX 4090 24GB | 1 |
| 数据盘 | 50GB |
使用步骤
0. 创建镜像
您可以参考平台的快速开始来创建镜像。 在选择镜像时,选择Diffrhythm: 
1. 启动webui
使用浏览器访问, 打开webui: 
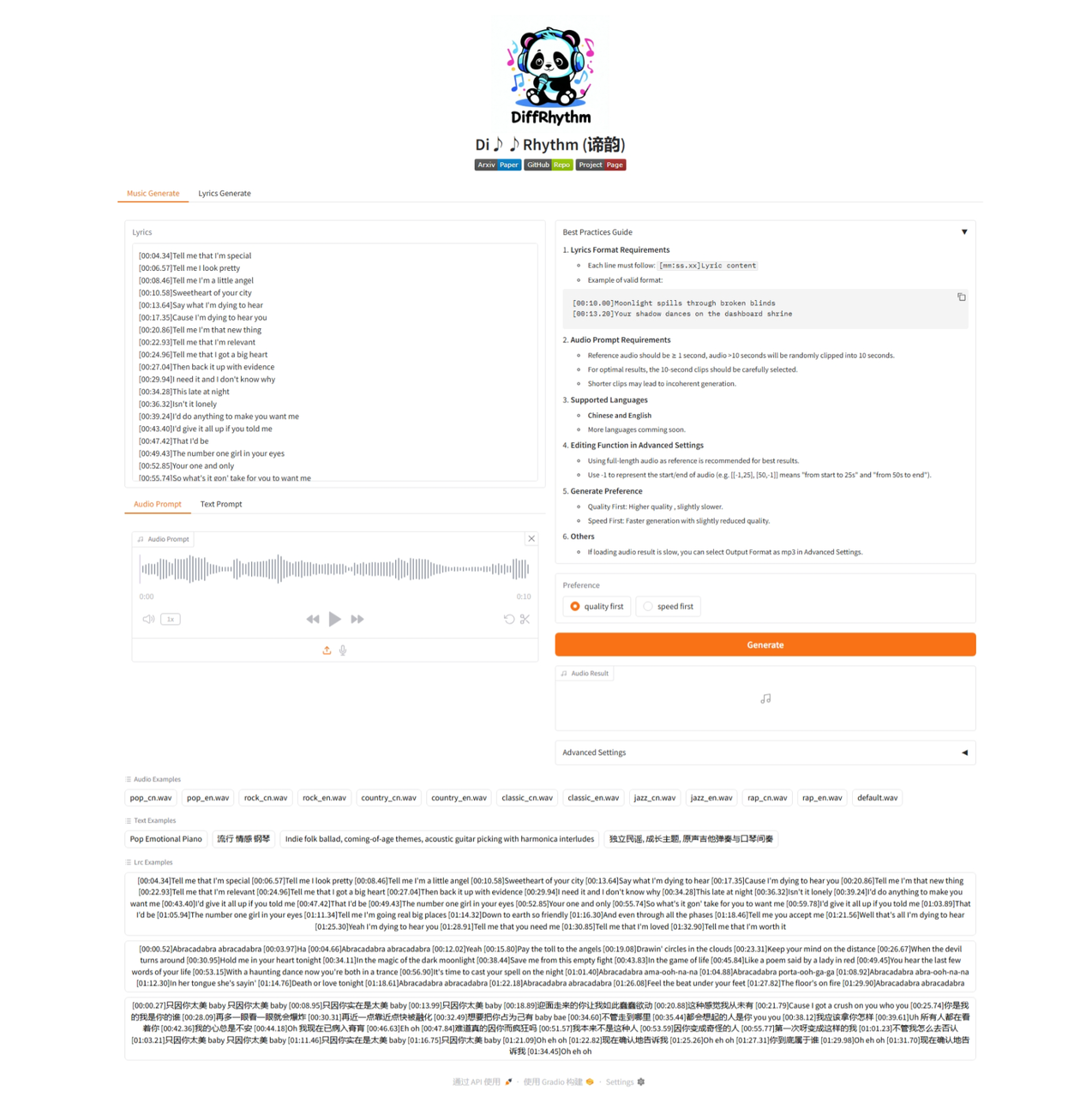
2. 生成歌曲
在webui的"Music Generate"界面,输入包含时间戳的歌词,“Audio Prompt”可以选择音乐使用的音色(可以上传音频文件或使用麦克风录制音频)或者在“Text Prompt”中输入音色的描述。webui页面最下方有多个示例,可以直接使用示例进行生成。 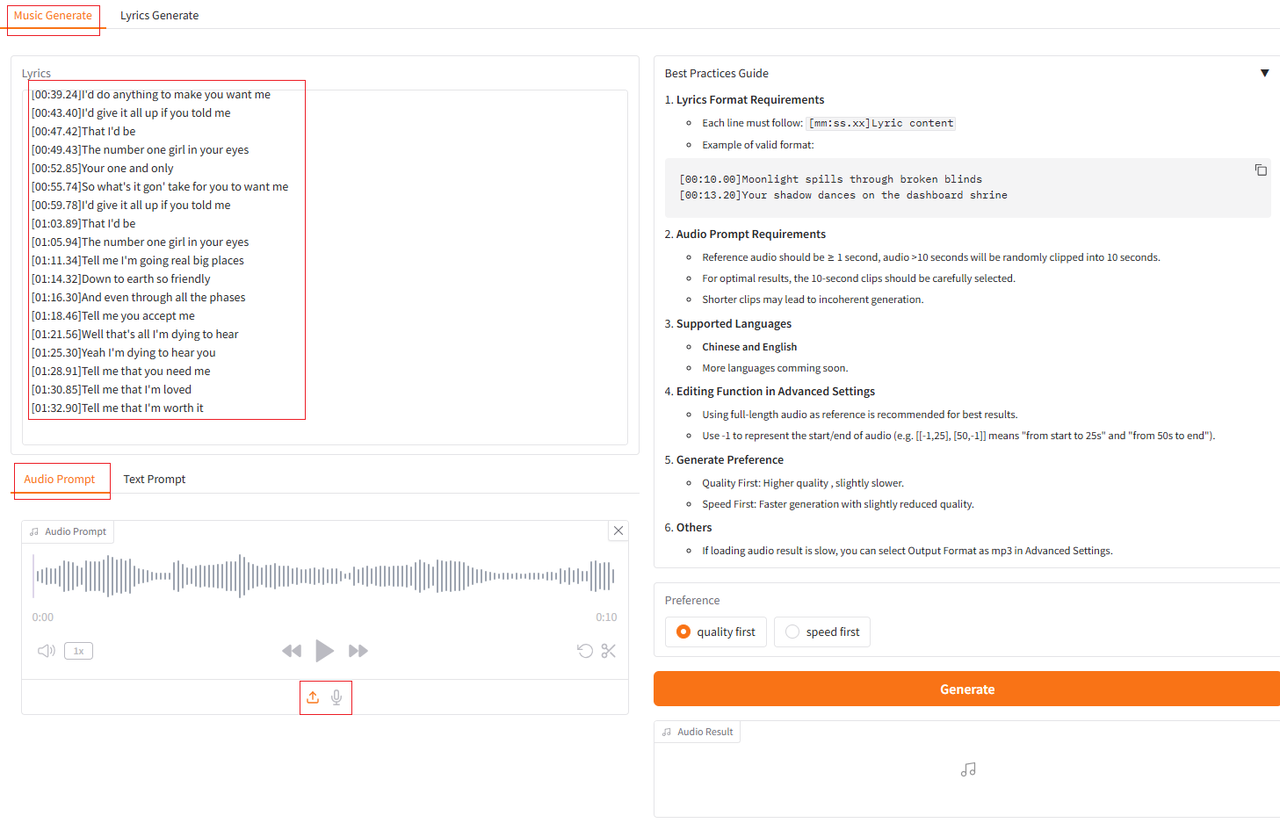
用户可以根据需要,在页面右侧进行设置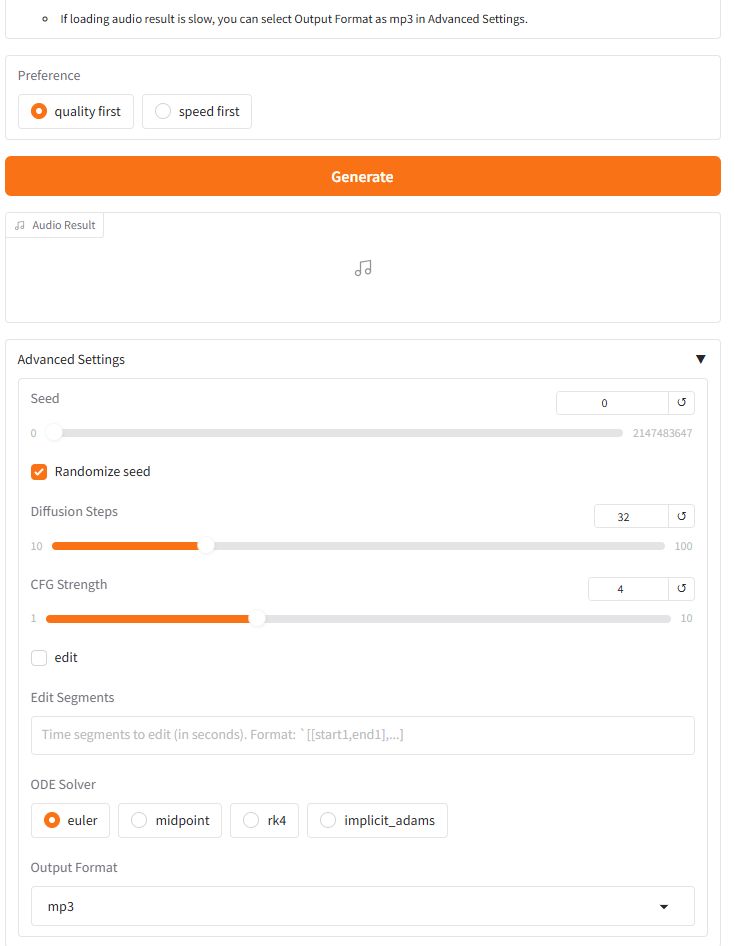 然后点击“Generate”按钮生成音乐。大约30~40秒可以生成音乐。若直接从网页上下载生成的音乐文件,该文件不存在后缀名,需要用户手动重命名该文件,添加对应的后缀名(查看“Output Format”),默认是mp3格式。 暂时无法在飞书文档外展示此内容
然后点击“Generate”按钮生成音乐。大约30~40秒可以生成音乐。若直接从网页上下载生成的音乐文件,该文件不存在后缀名,需要用户手动重命名该文件,添加对应的后缀名(查看“Output Format”),默认是mp3格式。 暂时无法在飞书文档外展示此内容
3. 歌词生成
左侧点击“Lyrics Generate”按钮,切换到歌词生成的界面 
镜像内置了ollama以及qwen2.5:14b模型,默认使用ollama的qwen2.5:14b模型生成歌词。先使用方法1从主题生成歌词,选择语言并输入主题和标签(主题和标签可以使用中文,可以在标签中限制歌曲时长,如“歌曲时长不超过1分45秒”),然后点击生成。 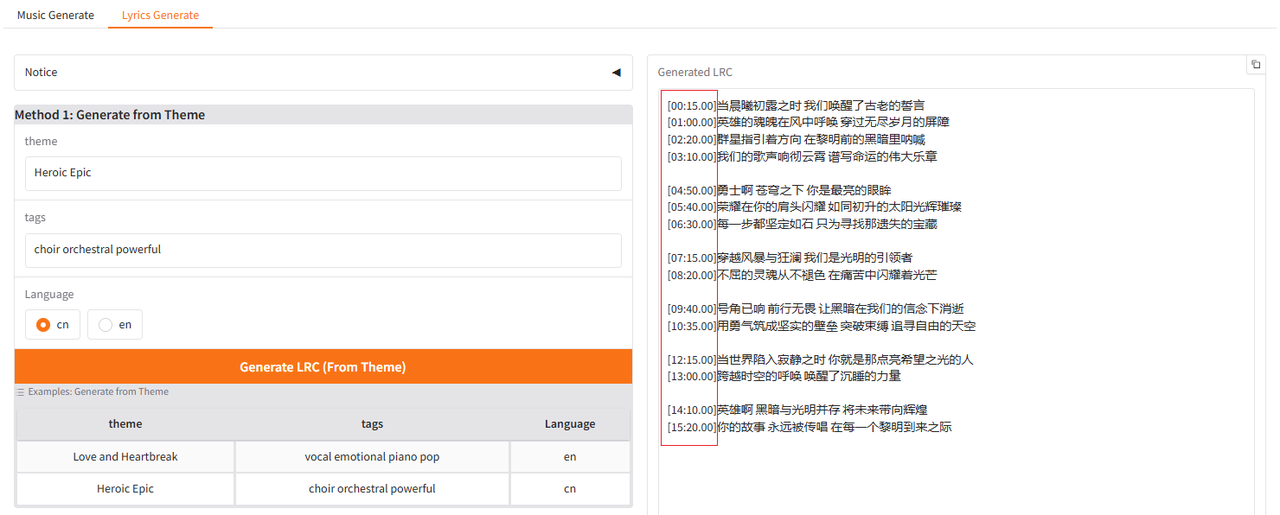
方法1生成的歌曲包含了时间戳。由于ollama的qwen2.5:14b能力较弱,所以歌词的时间戳可能存在跨度较大、标记空白的问题,用户需要手动删除这些时间戳和空白,然后复制歌词到方法2,为歌词添加时间戳 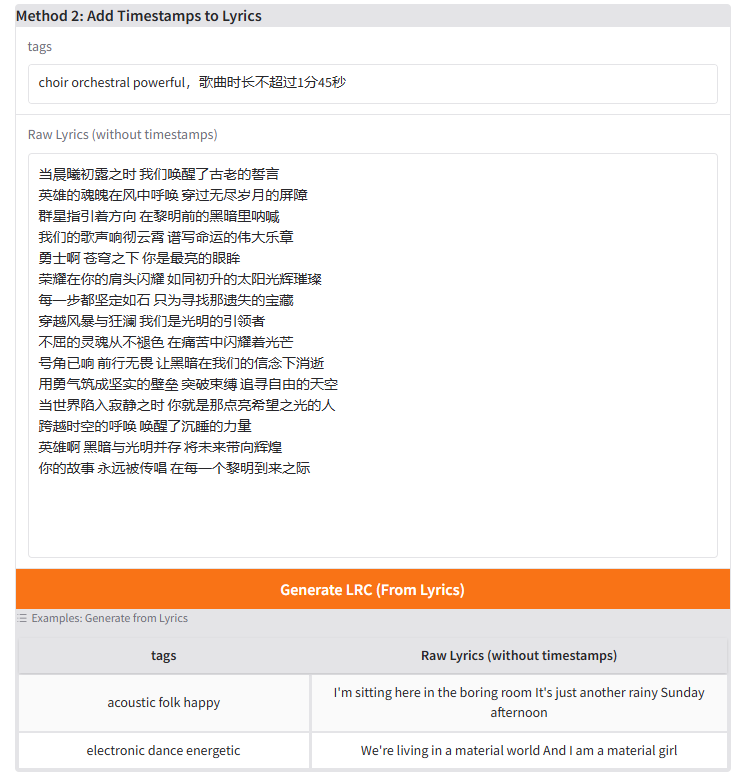
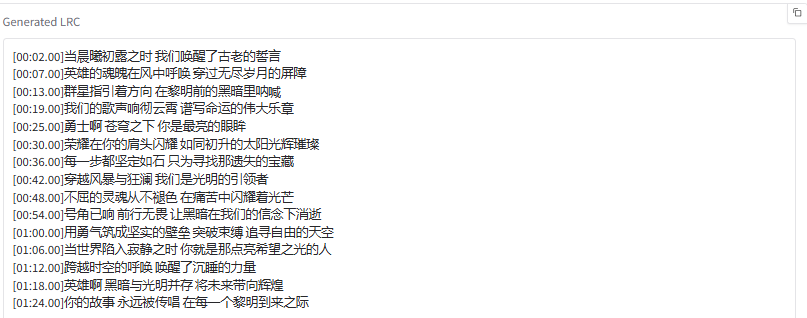
然后复制最终生成的歌词到歌曲生成界面,填写歌词和Text Prompt,点击生成按钮生成音乐 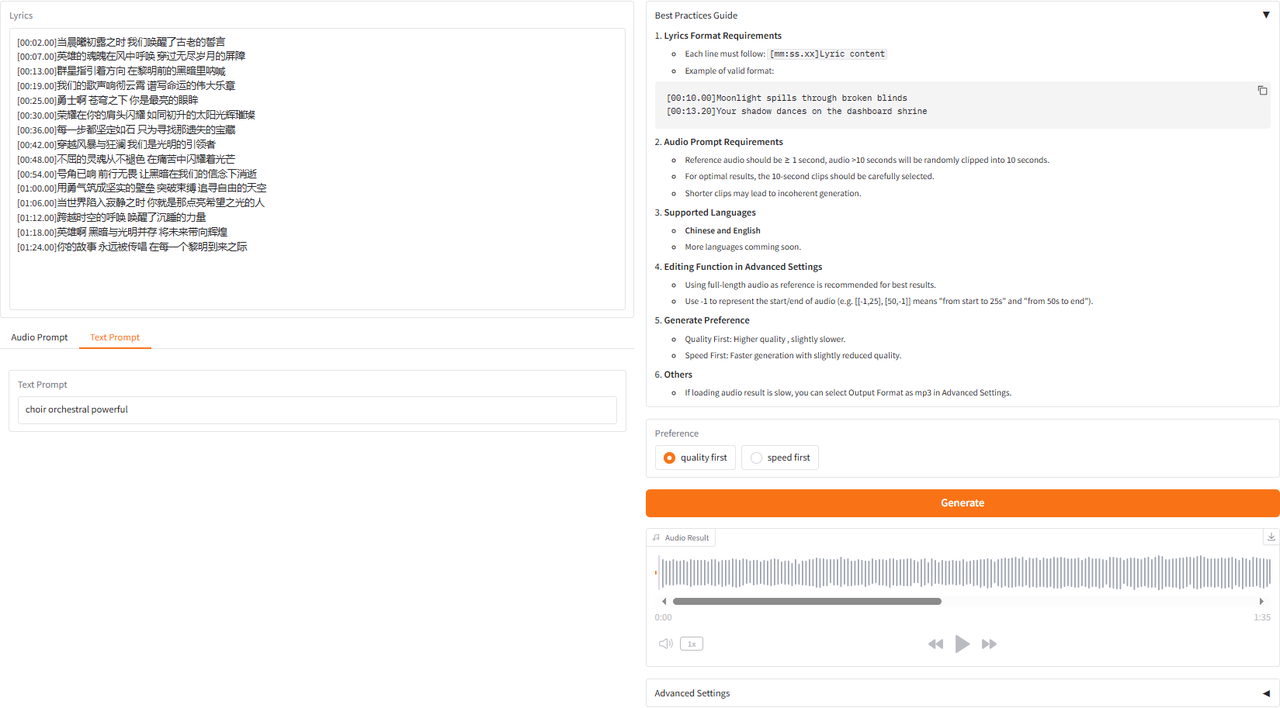
暂时无法在飞书文档外展示此内容 生成歌词也可以使用其他模型,用户可以自行配置。在实例界面点击“jupyterlab”按钮打开jupyterlab 
左侧的文件浏览器中可以看到文件“config.json”,右键点击该文件,在打开方式中选择“编辑器” 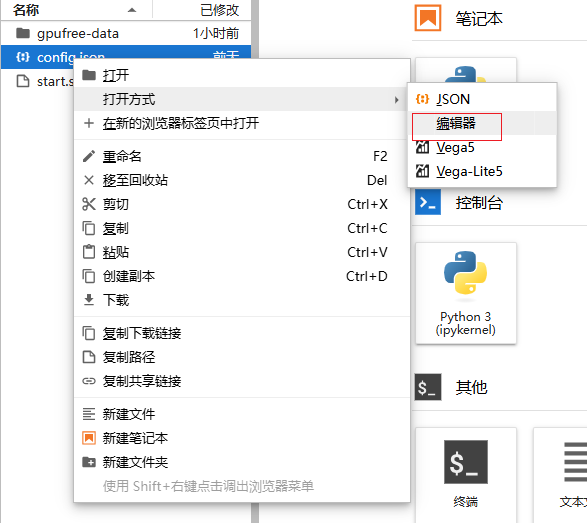
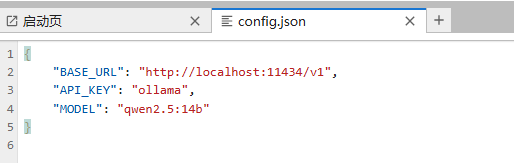
然后用户可以根据需要设置其他的ollama模型或者使用豆包、deepseek、gpt官方提供的大模型api。需要注意的是,使用ollama运行模型会占用一定显存,如果模型还没从显存中卸载(ollama默认5分钟不使用就从显存中卸载模型)就生成音乐,可能导致爆显存。所以尽量使用ollama运行较小的模型或者等待模型从显存中卸载再生成音乐。或者用户可以在jupyterlab的终端中,使用命令行立刻从显存中卸载模型
# 查看正在显存中的模型
ollama ps
# 将“<模型名称>”替换为查找到的模型的名称
ollama stop <模型名称>4. 补充
镜像使用的是最多生成1分35秒音乐的模型“DiffRhythm-1_2”,生成的音频长度固定为1分35秒。因此使用镜像生成的音频长度不能超过1分35秒,歌词中时间戳超过1分35秒的部分都会被截断,歌词太短也会导致生成的音频变成空白。目前使用“DiffRhythm-full”模型存在音频空白和音频时长固定4分45秒的问题,基本不可用。如果用户需要使用“DiffRhythm-full”模型,可以自行下载该模型并克隆官方项目使用