快速开始
资源需求
| 资源 | 数量 |
|---|---|
| RTX 4090 24GB | 2 |
| 数据盘 | 50GB |
使用步骤
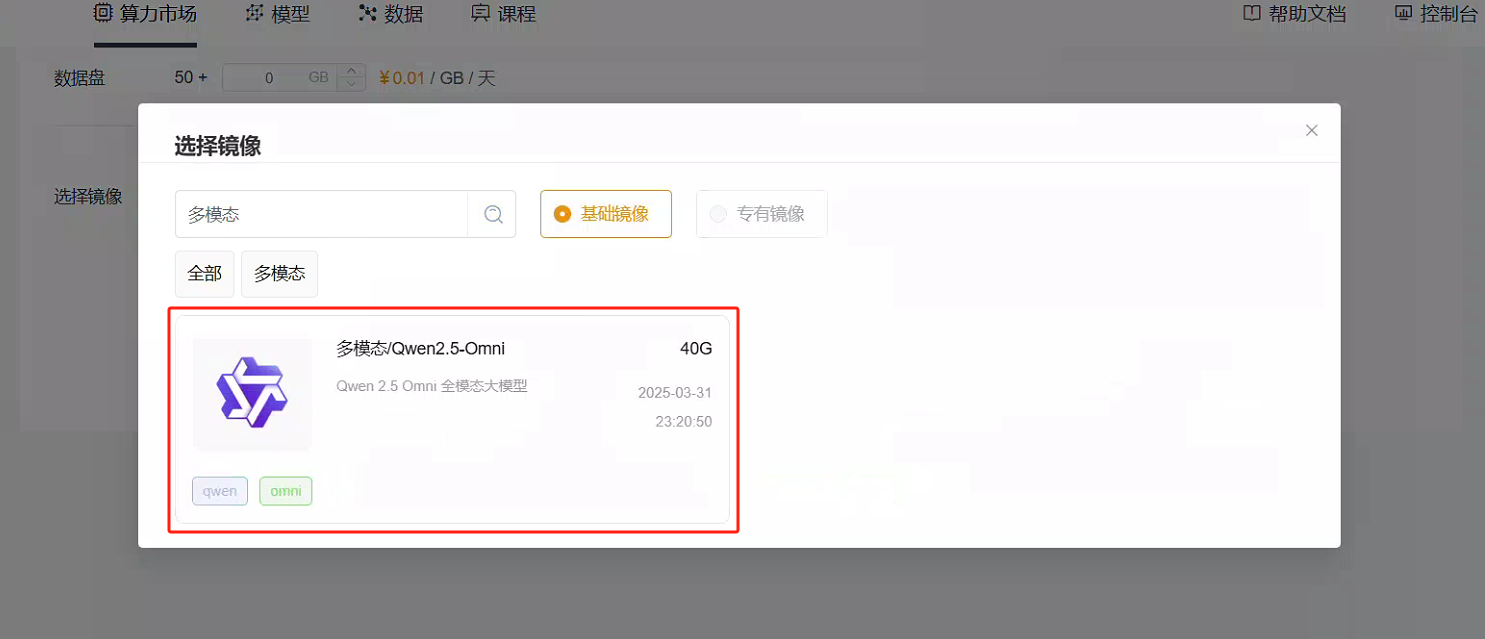
0. 创建镜像
您可以参考平台的快速开始来创建镜像。 在选择镜像时,选择Qweb-omni:
1. 启动webui
实例启动后约30秒模型加载完成,点击webui按钮即可启动服务 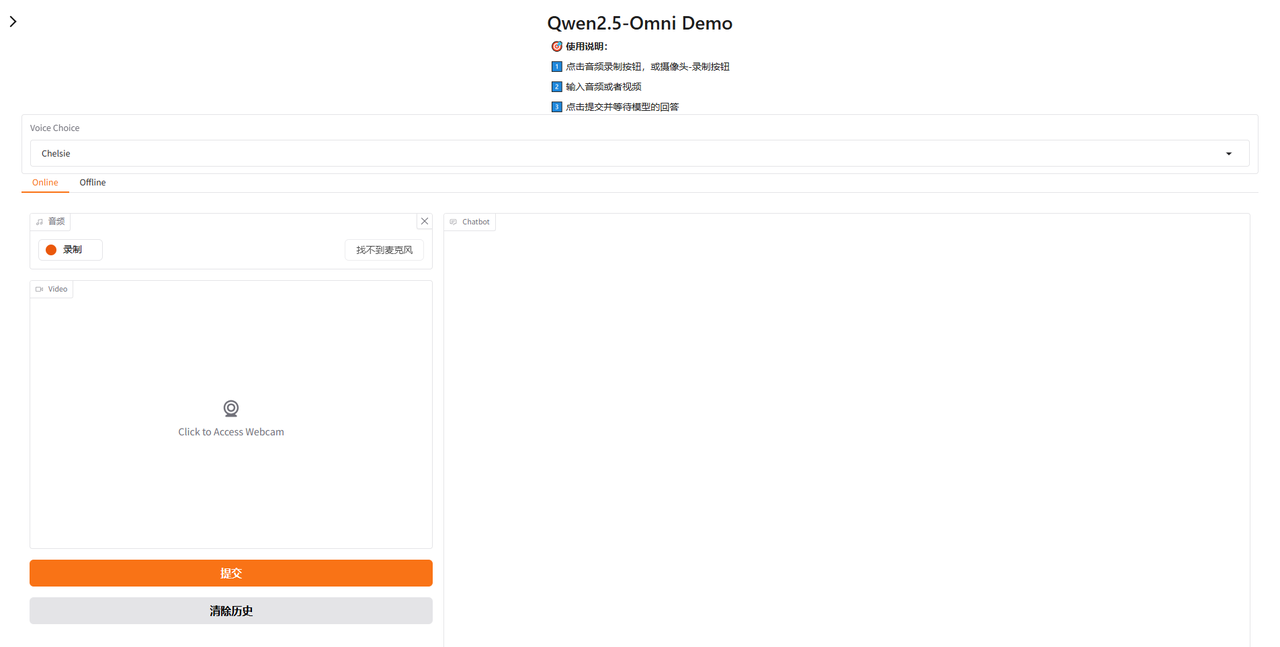
2. 配置webui
点击左上角的“<”,在弹出的侧边栏中可以设置系统提示词 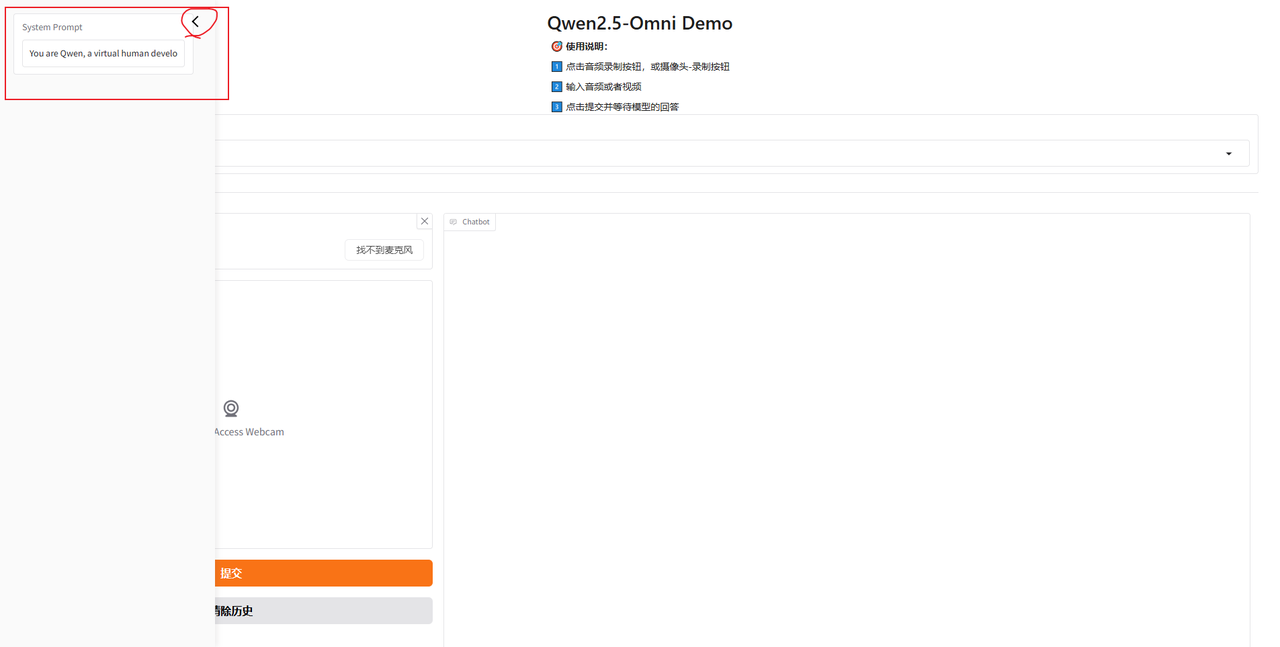
在Voice Choice中可以选择模型合成的音色,目前只有两种音色,默认为Chelsie(女声),可选Ethan(男声) 
下方可以选择交互模式,默认为online模式。
- online模式下: 可以选择音频交互模式(只需要打开麦克风)和视频交互(需要打开摄像头和麦克风)。
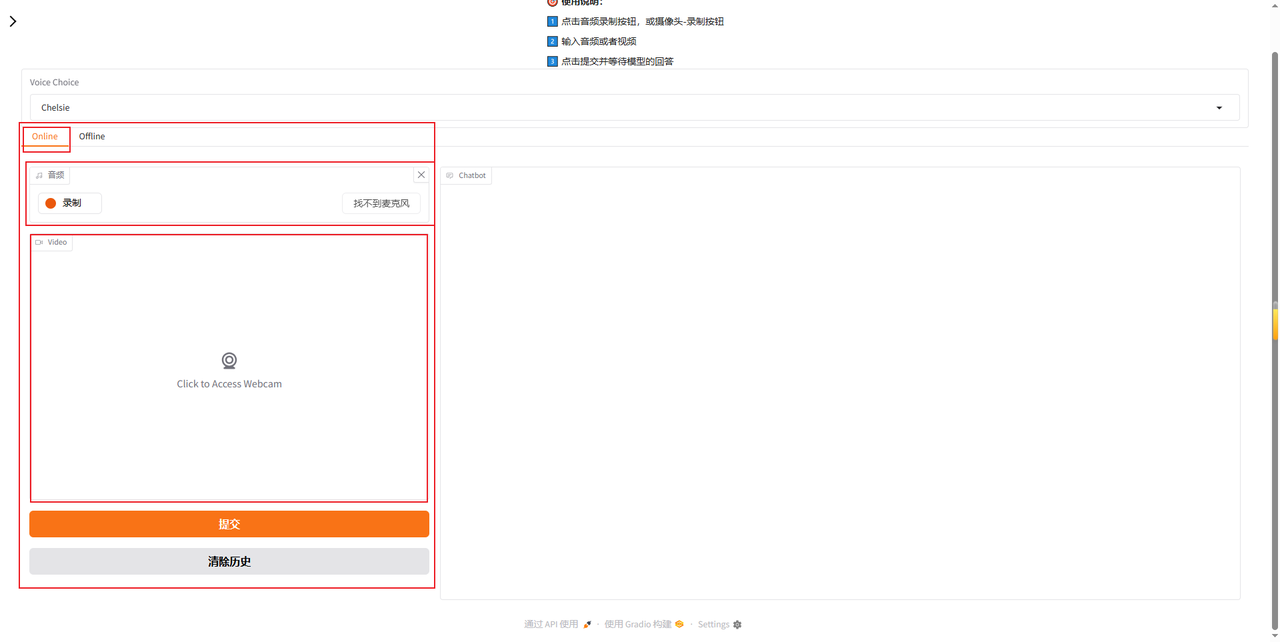
第一次使用音频交互或视频交互需要运行网页使用设备,根据需要允许使用即可 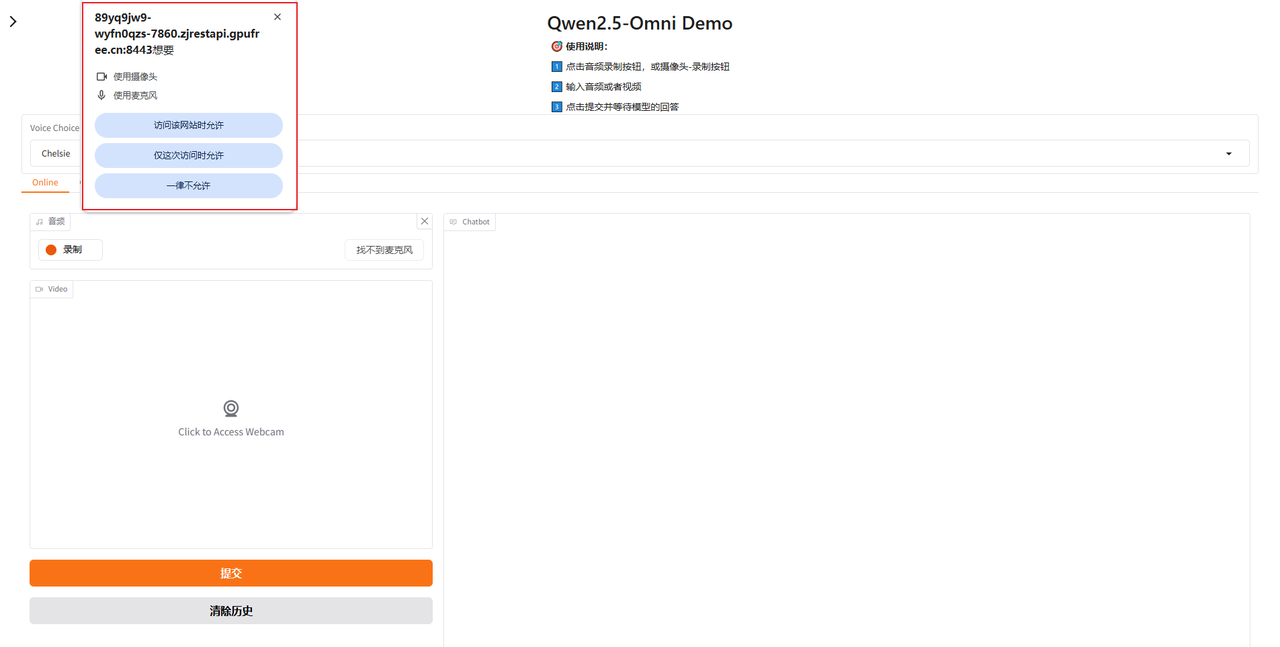
在这里,我们提问了“Qwen2.5 多模态大模型有什么特性“ 下面是输出结果: 
打开摄像头进行视频交互,视频交互需要更多资源与更长的推理时间,模型主要对视频中的音频进行解析,从音频中提取文本(用户的问题或指令)然后参考视频中的画面进行回答
- offline模式下: 可以上传音频、图片、视频和文本进行交互,也可以一次组合音视频、图片和文本进行交互(会消耗更多显存)
3. 交互
online模式: offline模式: 这里我们找了一小段线上课程讲解视频,本地上传,做为演示: 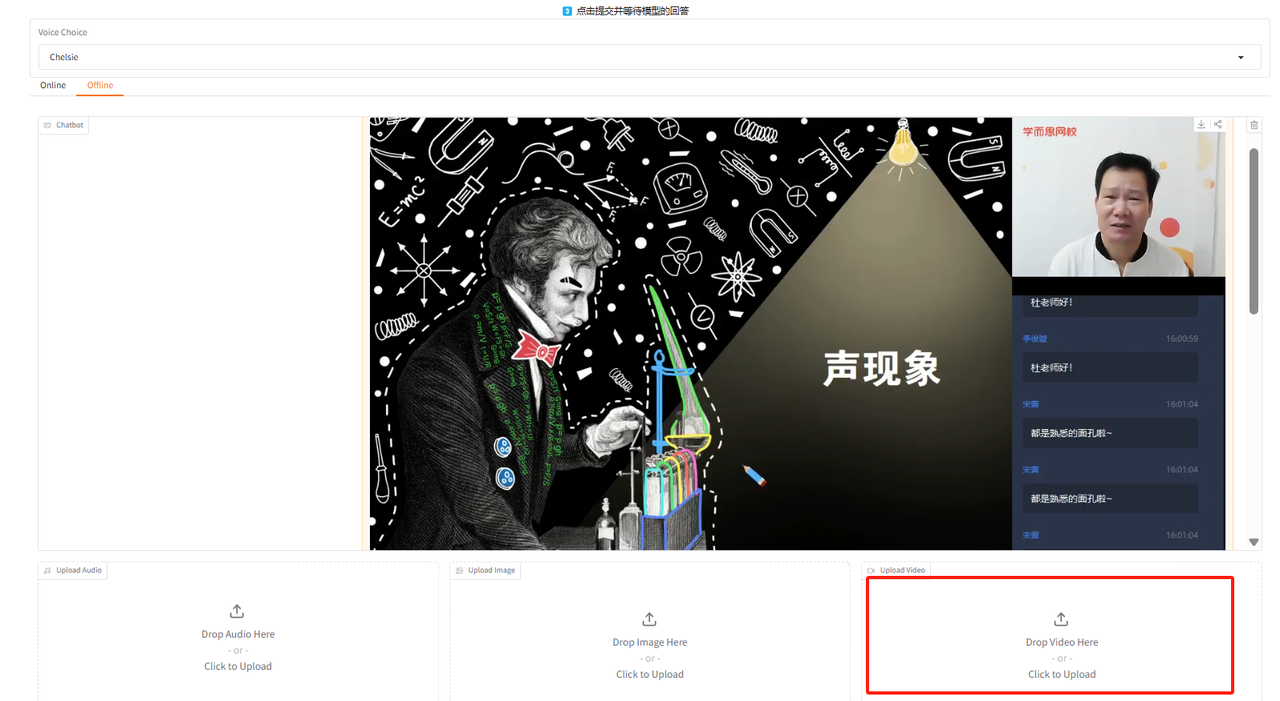
输出结果: 会看到对这部分视频的整体理解,如果想了解更多,可以进一步追问: 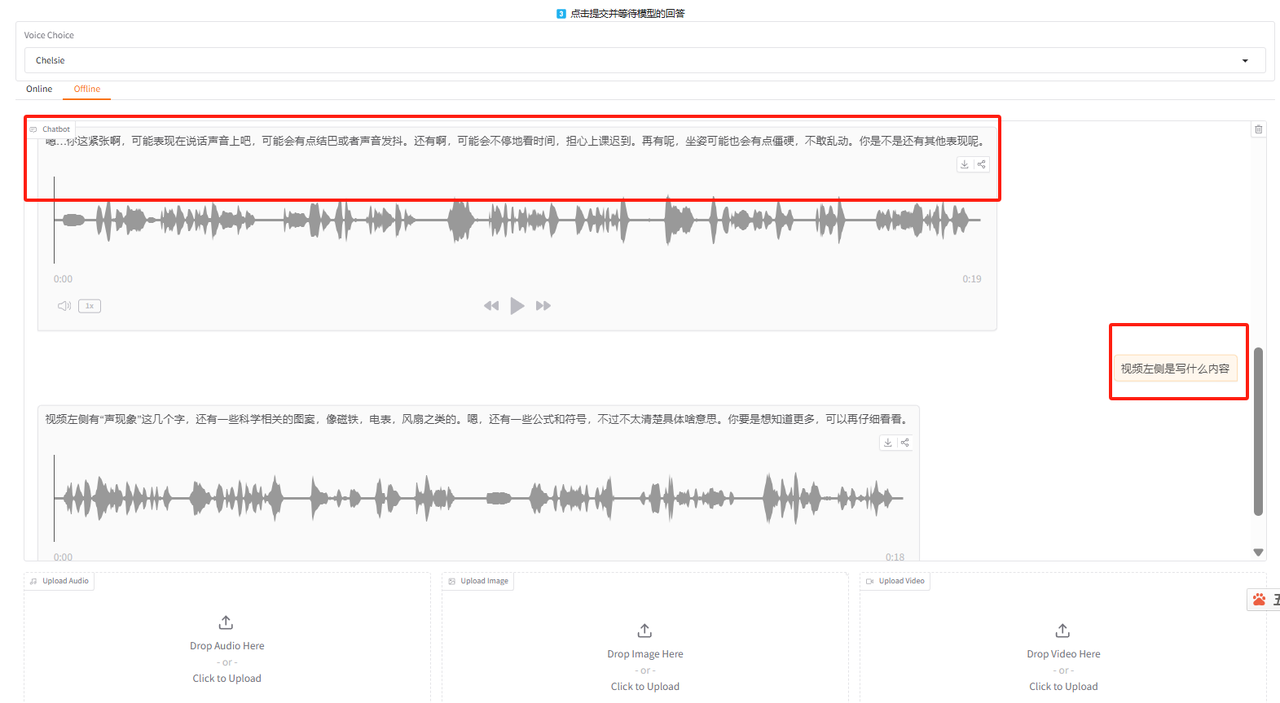
4. 资源消耗
在单张4090上,模型加载需要约21G显存。模型初次推理时会编译文件,需要约30秒,后续推理过程中,处理3秒包含音频的视频需要额外使用约1G显存,推理时间约20秒(解析视频占用大部分时间),纯音频则额外使用约1G显存,推理时间约5秒。音视频越长推理时间越久。
需要注意的是,使用双卡4090时,加载模型时卡1会占用21G显存,卡2会占用20G显存。但是推理时显存消耗只有几百M(消耗卡2的显存,10秒音频约300MB显存),推理速度差别不大。